Запеченный рулет из свинины Поркетта (Porchetta) , пошаговый рецепт на 10895 ккал, фото, ингредиенты
Добавить рецепт
Рецепт
Реклама
Видеорецепты по теме
Рецепт от юлии высоцкой
Ароматный рис
Юлия Высоцкая
Рецепт от юлии высоцкой
Зеленое ризотто
Ризотто изобрели в Венеции. Во всяком случае, итальянцы в этом убеждены! Секрет приготовления ризотто: рис не должен плавать в бульоне, но и ни в коем случае не должен пригорать. Нужно постараться
Юлия Высоцкая
Реклама
Видеорецепты по теме
Рецепт от юлии высоцкой
Куриное филе с помидорами и фасолью
К курице можно добавить и другие овощи, например морковь или сельдерей, а в качестве гарнира отлично подойдет рис. Готовое блюдо украсьте любой зеленью, которая вам нравится.
Юлия Высоцкая
Рецепт от юлии высоцкой
Яйца скрэмбл с пармезаном на тостах
На пару яйца скрэмбл получаются более нежными и воздушными, чем на сковороде, главное, чтобы во время приготовления дно вашей посуды не соприкасалось с поверхностью воды. Вместо пармезана можно
Юлия Высоцкая
Реклама
ВикторияS
Подготовка
1 день
Приготовление
4 часа
Рецепт на:
10 персон
ОПИСАНИЕ
Ни один праздник или ярмарка в Италии не обходятся без традиционного блюда — поркетты (Porchetta) — запеченного рулета из свинины, с румяной хрустящей кожей. Поркетта очень вкусна и в горячем, и в холодном виде.
По одной из версий впервые поркетту приготовили в центральной Италии, а потом у блюда появились поклонники по всей стране! Часто в Италии вы можете услышать приглашение: «Пойдем, на поркетту!». Существуют и кафе, и небольшие ресторанчики, специализирующиеся именно на поркетте. У каждого итальянца есть свое любимое место по ее приготовлению. Будете в Риме, непременно посетите в пригороде вечного города летнюю резиденцию Папы в Кастель Гандольфо, что на берегу озера Альбано. Там в маленьких семейных ресторанчиках вам подадут превосходную поркетту. Это я вам гарантирую!
Но вернемся к самому блюду. Обычно для приготовления поркетты используют годовалую свинью весом около 45-50 кг. Тушу тщательно потрошат и удалят кости, потом мясо приправляют разными специями и вином, после чего фаршируют им очищенную тушу, которую как можно туже перетягивают шпагатом.
Близятся новогодние праздники, и я вам очень рекомендую приготовить это вкусное мясное итальянское блюдо. Лично для меня с некоторых пор кусочек свежезапеченной поркетты ассоциируется именно с Новым годом и Рождеством! Ну что, приступим?!
В кулинарную книгу
С изображениямиБез изображений
В избранное
С изображениямиБез изображений
Пищевая ценность порции
1089
кКал
46%
| Белки | 26 г |
| Жиры | 109 г |
| Углеводы | 2 г |
% от дневной нормы
7 %
21 %
0 %
Основано на вашем
возрасте, весе и активности. Является справочной информацией.
Является справочной информацией.
Войдите или зарегистрируйтесь и мы сможем выводить вашу дневную норму потребления белков, жиров и углеводов
Войти/зарегистрироваться
ИНГРЕДИЕНТОВ НА
ПОРЦИЙ
Основные
свинина с жирком | 2 ⅕ кг |
| по вкусу |
перец черный свежемолотый | по вкусу |
чеснок | 5 зубчиков |
паприка сладкая | 1 ст. л. |
перец чили красный | по вкусу |
розмарин сушеный | 1 ч. л. |
орегано сушеный | по вкусу |
фенхель семена | 1 ч. л. |
Выделить все
фотоотчеты к рецепту0
Добавить фотографию
Пока нет ни одной фотографии с приготовлением этого блюда
Добавить фотографию
Пошаговый рецепт с фото
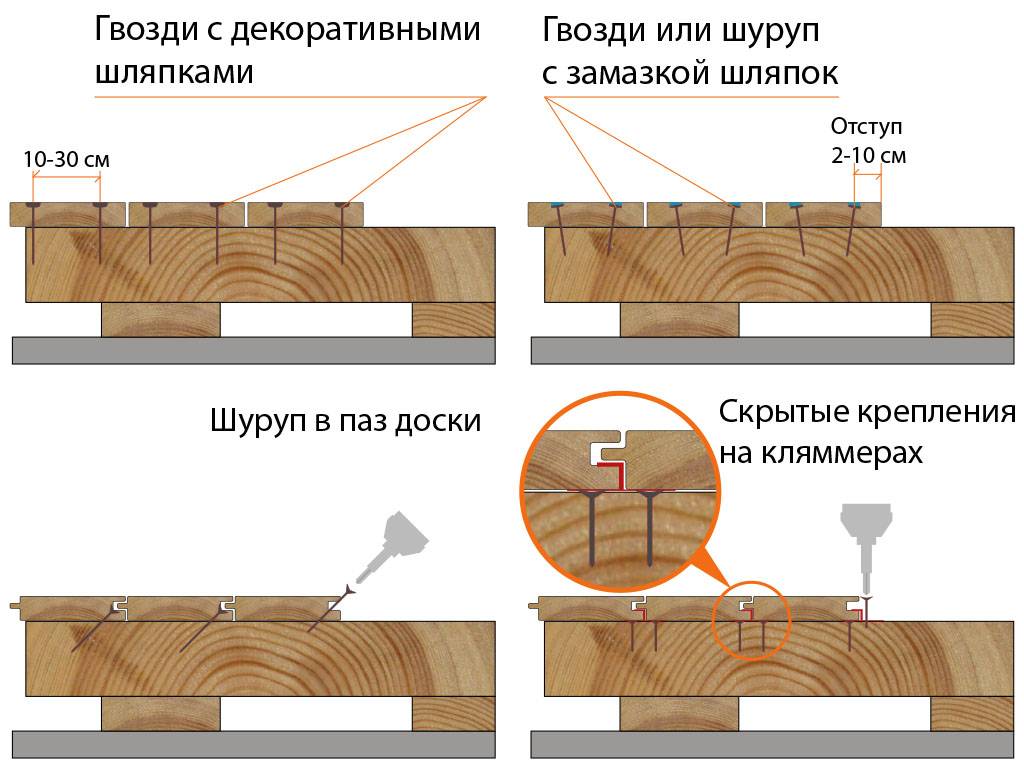
Для начала необходимо правильно выбрать мясо для поркетты. При покупке стоит выбирать кусок брюшины с максимальным количеством мяса, а не сала и обязательно с кожей. Кусок свиной брюшины (прямоугольной формы) протрите влажным полотенцем, удалите пленки, срежьте лишний жир. Реберные кости, если таковые имеются, аккуратно удалите.
При покупке стоит выбирать кусок брюшины с максимальным количеством мяса, а не сала и обязательно с кожей. Кусок свиной брюшины (прямоугольной формы) протрите влажным полотенцем, удалите пленки, срежьте лишний жир. Реберные кости, если таковые имеются, аккуратно удалите.
Далее положите кусок брюшины шкурой вниз. С помощью ножа сделайте неглубокие насечки (в виде больших ромбов). Посолите по вкусу, выложите крупно рубленный чеснок. Посыпьте хлопьями паприки, перцем и пряными травами — розмарином, орегано, семенами фенхеля. Хорошо промассируйте и вотрите специи в разрезы мяса.
Сверните кусок мяса в плотный рулет. Затем свяжите рулет кулинарной нитью, жгутами, зафиксировав его форму.
Оберните подготовленную поркетту в пекарскую бумагу, чтобы при запекании кожа не пригорела и не прилипала к фольге. Затем уже в бумаге заверните поркетту в двойной слой фольги и уберите на сутки в холодильник. Мясо за это время должно хорошо промариноваться в чесноке и специях.
Через сутки выложите поркетту на противень и запекайте в разогретой до 150ºС — 160ºС духовке около 3 часов. После запекания достаньте поркетту из духовки, аккуратно снимите фольгу и бумагу с поркетты. Рулет выложите на застеленный новым куском пекарской бумаги противень. После чего увеличьте температуру духовки до 200ºС. Далее поместите поркетту снова в духовку минут на 30, чтобы свиная шкура подрумянилась, запеклась и стала хрустящей. Во время запекания необходимо часто переворачивать поркетту, чтобы она равномерно запеклась и стала хрустящей. Когда шкура запеклась, нужно достать поркетту, дать ей минут «отдохнуть» в течение 15 мин.
Аккуратно снимите шпагат, дайте поркетте немного остыть, нарежьте на порционные куски и подавайте к столу.
К поркетте можно подать ваши любимые соусы, а также свежие или запеченные овощи. Ну и, конечно же, с использованием поркетты приготовить панини (панино) — излюбленный итальянский сэндвич. Buon appetito!
поделиться фото
согласны?
Показать всех
ГОЛОСА ЗА РЕЦЕПТ ДНЯ(14)
ГОЛОСА ЗА НЕСЛАДКИЙ РЕЦЕПТ МЕСЯЦА(3)
Теги рецепта
итальянская кухнявыпекать, запекатьосновные блюдазапеченная
Реклама
Реклама
РЕЙТИНГ РЕЦЕПТА
РАССКАЗАТЬ ДРУЗЬЯМ
Фильтры
Сбросить все
Подборки
Рецепты месяца
Быстрые рецепты
Правильное питание (пп-рецепты)
Праздничный обед
Весенние салаты
Десерты с чаем матча
Рецепты любимых напитков
Ингредиенты
Добавить к поиску
и или
Исключить ингредиент
Пользователи
Показать
Итальянская поркетта из свинины в домашних условиях рецепт с фото
Итальянская поркетта из свинины в домашних условиях
К сожалению, у вас выключен или не работает Javascript. Для работы с большинством функций на нашем сайте это необходимый элемент. Обратитесь к своему администратору, чтобы решить эту проблему.
Для работы с большинством функций на нашем сайте это необходимый элемент. Обратитесь к своему администратору, чтобы решить эту проблему.
Состав / ингредиенты
14
Изменить состав
порций:
Время приготовления: 3 ч 50 мин PT3H50M
Для приготовления этого вкуснейшего блюда нам понадобится пласт мяса без костей (свиное плечо) толщиной 2,5 см размером примерно 25 на 35 см.
Первым делом подготавливаем продукты:
— очищаем от шелухи лук, затем разрезаем его на половинки и каждую тонко шинкуем;
— моем фенхель, обсушиваем бумажными полотенцами, затем луковицу тонко режем, а листья мелко рубим;
— колбасу очищаем от оболочки и нарезаем на маленькие кусочки;
— вымытый и обсушенный свежий розмарин мелко рубим;
— чистим от шелухи зубчики чеснока, а заем их тонко нарезаем пластиками или же брусочками — по желанию;
— тщательно моем под проточной водой яйца, вытираем бумажным полотенцем;
— очищаем красный лук и режем каждую луковичку на половинки. Если же лук крупный, то можно порезать луковицы на четвертинки или еще мельче;
Если же лук крупный, то можно порезать луковицы на четвертинки или еще мельче;
— мясо моем и обсушиваем при помощи бумажных полотенец;
— подготавливаем нужные специи, масло и раскладываем все в отдельные мисочки.
Когда все готово, можно начинать! Итак:
1. В большую сковороду наливаем половину от указанного количества оливкового масла, нагреваем его на среднем огне. Затем огонь убавляем, выкладываем в сковороду нашинкованный лук, а также фенхель (луковицу). Обжариваем все вместе, периодически мешая, в течение 10 минут (до размягчения овощей).
2. Выкладываем в ту же сковороду нарезанную колбасу, а также насыпаем семена фенхеля и кладем нарубленный розмарин, измельченный чеснок, посыпаем все черным молотым перцем. Обжариваем все, перемешивая, в течение 5 минут. Кусочки колбасы должны подрумяниться. Далее посыпаем содержимое сковороды солью, снова мешаем. Перекладываем полученную смесь на плоскую тарелку подходящего размера и даем остыть до комнатной температуры.
3. Включаем разогреваться духовку до 180 градусов по Цельсию. Подготовленный красный лук выкладываем на дно формы. Свинину кладем на рабочую поверхность, посыпаем солью и черным молотым перцем, втирая их в мясо. Потом выкладываем на пласт свинины колбасный фарш, равномерно распределяем, оставляя с боков пустые места шириной примерно 2,5 см. Далее сворачиваем пласт в рулет по длинной стороне, довольно плотно, и перевязываем кухонным шпагатом с интервалом в 2-3 см. Сверху рулет натираем оставшимся оливковым маслом и выкладываем его в форму поверх красного лука.
4. Ставим форму в успевшую разогреться духовку на 2,5 часа. Время от времени заглядываем в духовку и поливаем поркетту сверху выделившимся соком. Мясо должно стать мягким. Возможно, понадобится увеличить время приготовления на полчаса. Готовый рулет выкладываем на разделочную доску и даем ему там полежать в течение 15 минут.
Поркетта готова! Все что осталось — это нарезать ее ломтиками и красиво подать к столу. Кстати, идеально к ней подойдет вкусное красное вино.
Кстати, идеально к ней подойдет вкусное красное вино.
Приятного аппетита!
Для чего нужен этот код?
Внимание! В телефоне/планшете должно быть установлено специальное приложение.
<a href=»/about-qr-code» target=»_blank»>Читать более подбробно об этом коде</a>.»>
Похожие рецепты
Остальные категории
Вторые горячие блюда
Овощи в духовке запеченные приготовление пошагово
Праздничный стол
Мясо с луком
Итальянская кухня
Яйца с чесноком пошаговые рецепты
Рецепты без сливочного масла и маргарина
Второе из мяса
Средиземноморская кухня рецепты
Национальные кухни
Рецепты на 8 марта
Калорийность продуктов, возможных в составе блюда
- Лук — 41 ккал/100г
- Яйцо куриное — 157 ккал/100г
- Яичный белок — 45 ккал/100г
- Яичный порошок — 542 ккал/100г
- Яичный желток — 352 ккал/100г
- Яйцо страуса — 118 ккал/100г
- Свинина жирная — 333 ккал/100г
- Свинина мясная — 357 ккал/100г
- Свинина — нежирное жаркое — 184 ккал/100г
- Свинина — отбивная на косточке — 537 ккал/100г
- Свинина — шницель — 352 ккал/100г
- Свинина — плечо — 593 ккал/100г
- Окорок кабана — 113 ккал/100г
- Свинина — 259 ккал/100г
- Чеснок — 143 ккал/100г
- Перец черный молотый — 255 ккал/100г
- Фенхель — 49 ккал/100г
- Соль — 0 ккал/100г
- Лук репчатый — 41 ккал/100г
- Оливковое масло — 913 ккал/100г
- Розмарин свежий — 131 ккал/100г
- Салями — 568 ккал/100г
Чтение и запись данных — документация Apache Arrow Python Cookbook

Дан массив из 100 чисел от 0 до 99
импортировать numpy как np
импортировать pyarrow как pa
массив = pa.array (np.arange (100))
print(f"{обр[0]} .. {обр[-1]}")
0 .. 99
Чтобы записать его в файл Parquet,
поскольку Parquet — это формат, который содержит несколько именованных столбцов,
мы должны создать pyarrow . Таблица из него,
чтобы мы получили таблицу из одного столбца, которую затем можно
записывается в файл Parquet.
таблица = pa.Table.from_arrays([arr], имена=["col1"])
Когда у нас есть таблица, ее можно записать в файл Parquet.
используя функции модуля pyarrow.parquet
импортировать pyarrow.parquet как pq pq.write_table (таблица, "example.parquet", сжатие = нет)
Имея файл Parquet, его можно прочитать обратно в pyarrow . Таблица с помощью функции pyarrow.parquet.read_table()
импортировать pyarrow.parquet как pq таблица = pq.read_table("пример.паркет")
 read_table("пример.паркет")
read_table("пример.паркет")
Результирующая таблица будет содержать те же столбцы, которые существовали в
файл паркета как ChunkedArray
принт(таблица)
pyarrow.Таблица столбец1: int64 ---- столбец1: [[0,1,2,3,4,...,95,96,97,98,99]]
При чтении файла Parquet с помощью pyarrow.parquet.read_table() можно ограничить, какие столбцы и строки будут прочитаны
в память с помощью фильтры и столбцы аргументы
импортировать pyarrow.parquet как pq
таблица = pq.read_table("пример.паркет",
столбцы = ["col1"],
фильтры=[
("столб1", ">", 5),
("столб1", "<", 10),
])
Результирующая таблица будет содержать только спроецированные столбцы
и отфильтрованные строки. См. pyarrow.parquet.read_table() документацию для получения подробной информации о синтаксисе фильтров.
принт(таблица)
pyarrow.Таблица столбец1: int64 ---- столбец1: [[6,7,8,9]]
Помимо использования стрелки для чтения и сохранения распространенных форматов файлов, таких как Parquet, можно выгружать данные в формате необработанных стрелок, что позволяет прямое отображение данных с диска в память. Этот формат называется формат Arrow IPC.
Дан массив из 100 чисел от 0 до 99
импортировать numpy как np
импортировать pyarrow как pa
массив = pa.array (np.arange (100))
print(f"{обр[0]} .. {обр[-1]}")
0 .. 99
Мы можем сохранить массив, создав pyarrow.RecordBatch .
из него и записать пакет записи на диск.
схема = pa.schema([
pa.field('числа', тип обр.)
])
с pa.OSFile('arraydata.arrow', 'wb') в качестве приемника:
с pa.ipc.new_file(sink, schema=schema) в качестве записи:
пакет = pa.record_batch([arr], схема=схема)
писатель.write(пакет)
Если бы мы сохранили несколько массивов в один и тот же файл,
нам просто нужно адаптировать схему соответственно и добавить
их всех на вызов record_batch .
Массивы Arrow, которые были записаны на диск в Arrow IPC формат может быть отображен обратно в память непосредственно с диска.
с pa.memory_map('arraydata.arrow', 'r') в качестве источника:
загруженные_массивы = pa.ipc.open_file(источник).read_all()
обр = загруженные_массивы[0]
print(f"{обр[0]} .. {обр[-1]}")
0 .. 99
Можно написать Arrow pyarrow.Таблица 9с 0012 по
файл CSV с использованием функции pyarrow.csv.write_csv()
обр = pa.массив (диапазон (100))
таблица = pa.Table.from_arrays([arr], имена=["col1"])
импортировать pyarrow.csv
pa.csv.write_csv(таблица, "table.csv",
write_options=pa.csv.WriteOptions(include_header=True))
Если вам нужно постепенно записывать данные в файл CSV
когда вы создаете или извлекаете данные, и вы не хотите хранить
в памяти сразу всю таблицу записать, можно использовать pyarrow.csv.CSVWriter для постепенной записи данных
схема = pa.
 schema([("col1", pa.int32())])
с pa.csv.CSVWriter("table.csv", схема=схема) в качестве записи:
для чанка в диапазоне (10):
datachunk = диапазон (фрагмент * 10, (фрагмент + 1) * 10)
таблица = pa.Table.from_arrays([pa.array(datachunk)], схема=схема)
писатель.write(таблица)
schema([("col1", pa.int32())])
с pa.csv.CSVWriter("table.csv", схема=схема) в качестве записи:
для чанка в диапазоне (10):
datachunk = диапазон (фрагмент * 10, (фрагмент + 1) * 10)
таблица = pa.Table.from_arrays([pa.array(datachunk)], схема=схема)
писатель.write(таблица)
С таким же успехом можно написать pyarrow.RecordBatch передавая их, как для таблиц.
Стрелка может читать pyarrow.Table объектов из CSV с использованием
оптимизированный путь кода, который может использовать несколько потоков.
импорт pyarrow.csv
таблица = pa.csv.read_csv("table.csv")
Arrow сделает все возможное, чтобы вывести типы данных. Дополнительные варианты могут быть
предоставляется pyarrow.csv.read_csv() для управления pyarrow.csv.ConvertOptions .
принт(таблица)
pyarrow.Таблица столбец1: int64 ---- столбец1: [[0,1,2,3,4,...,95,96,97,98,99]]
Когда ваш набор данных большой, обычно имеет смысл разделить его на
несколько отдельных файлов. Вы можете сделать это вручную или использовать
Вы можете сделать это вручную или использовать pyarrow.dataset.write_dataset() , чтобы позволить Arrow выполнить работу
разделения данных на куски для вас.
Аргумент разделения позволяет сообщить pyarrow.dataset.write_dataset() для каких столбцов данные должны быть разделены.
Например, учитывая 100 дней рождения в 2000 и 2009 годах
импорт numpy.random
данные = pa.table({"день": numpy.random.randint(1, 31, размер=100),
«месяц»: numpy.random.randint (1, 12, размер = 100),
"year": [2000 + x // 10 для x в диапазоне (100)]})
Затем мы могли бы разделить данные по столбцу года так, чтобы они сохраняется в 10 разных файлах:
импортировать пирроу как па
импортировать pyarrow.dataset как ds
ds.write_dataset(данные, "./partitioned", format="parquet",
partitioning=ds.partitioning(pa.schema([("год", pa.int16())])))
Arrow будет разделять наборы данных в подкаталогах по умолчанию, что в результате получается 10 разных каталогов, названных со значением разбиения каждый столбец с файлом, содержащим подмножество данных для этого раздела:
из pyarrow import fs localfs = fs.
 LocalFileSystem()
partitioned_dir_content = localfs.get_file_info(fs.FileSelector("./partitioned", recursive=True))
files = sorted((f.path для f в partitioned_dir_content, если f.type == fs.FileType.File))
для файла в файлах:
распечатать файл)
LocalFileSystem()
partitioned_dir_content = localfs.get_file_info(fs.FileSelector("./partitioned", recursive=True))
files = sorted((f.path для f в partitioned_dir_content, если f.type == fs.FileType.File))
для файла в файлах:
распечатать файл)
./partitioned/2000/part-0.паркет ./partitioned/2001/part-0.паркет ./partitioned/2002/part-0.паркет ./partitioned/2003/part-0.паркет ./partitioned/2004/part-0.паркет ./partitioned/2005/part-0.паркет ./partitioned/2006/part-0.паркет ./partitioned/2007/part-0.паркет ./partitioned/2008/part-0.паркет ./разделено/2009/part-0.паркет
В некоторых случаях набор данных может состоять из нескольких отдельных файлы, каждый из которых содержит часть данных.
В этом случае функция pyarrow.dataset.dataset() предоставляет
интерфейс для обнаружения и чтения всех этих файлов как единого большого набора данных.
Например, если у нас есть такая структура:
примеров/ ├── dataset1.parquet ├── dataset2.
 parquet
└── dataset3.parquet
parquet
└── dataset3.parquet
Затем, указав pyarrow.dataset.dataset() в каталог примеров обнаружит эти паркетные файлы и выставит их все как один pyarrow.dataset.Набор данных :
импортировать pyarrow.dataset как ds
набор данных = ds.dataset("./examples", format="parquet")
печать (набор данных.файлы)
['./examples/dataset1.parquet', './examples/dataset2.parquet', './examples/dataset3.parquet']
Весь набор данных можно просмотреть как одну большую таблицу, используя pyarrow.dataset.Dataset.to_table() . При этом каждая паркетная пилка
содержит только 10 строк, преобразование набора данных в таблицу
выставить их как единую таблицу.
таблица = набор данных.to_table() печать (таблица)
pyarrow.Таблица столбец1: int64 ---- столбец1: [[0,1,2,3,4,5,6,7,8,9],[10,11,12,13,14,15,16,17,18,19],[20, 21,22,23,24,25,26,27,28,29]]
Обратите внимание, что преобразование в таблицу приведет к принудительной загрузке всех данных
в памяти. Для больших наборов данных обычно это не то, что вам нужно.
Для больших наборов данных обычно это не то, что вам нужно.
По этой причине лучше полагаться на метод pyarrow.dataset.Dataset.to_batches() , который
итеративно загружать набор данных по одному фрагменту данных за раз, возвращая pyarrow.RecordBatch для каждого из них.
для record_batch в dataset.to_batches():
col1 = record_batch.column("col1")
print(f"{col1._name} = {col1[0]} .. {col1[-1]}")
столбец1 = 0 .. 9 столбец1 = 10 .. 19 столбец1 = 20 .. 29
pyarrow.dataset.Dataset также может абстрагироваться
секционированные данные, поступающие из удаленных источников, таких как S3 или HDFS.
из pyarrow import fs
# Список содержимого s3://ursa-labs-taxi-data/2011
s3 = fs.SubTreeFileSystem(
"урса-лабс-такси-данные",
fs.S3FileSystem(region="us-east-2", анонимно=True)
)
для записи в s3.get_file_info(fs.FileSelector("2011", recursive=True)):
если entry.type == fs.FileType.File:
печать (вход. путь)
 путь)
путь)
2011/01/данные.паркет 2011/02/данные.паркет 2011/03/данные.паркет 2011/04/данные.паркет 2011/05/данные.паркет 2011/06/data.паркет 2011/07/данные.паркет 2011/08/данные.паркет 2011/09/data.паркет 2011/10/данные.паркет 2011/11/данные.паркет 2011/12/данные.паркет
Данные в корзине могут быть загружены как один большой набор данных, разделенный на разделы.
к месяцу с использованием
набор данных = ds.dataset("s3://ursa-labs-taxi-data/2011",
разбиение = ["месяц"])
для f в dataset.files[:10]:
печать (е)
Распечатать("...")
ursa-labs-taxi-data/2011/01/data.parquet ursa-labs-taxi-data/2011/02/data.parquet ursa-labs-taxi-data/2011/03/data.parquet ursa-labs-taxi-data/2011/04/data.parquet ursa-labs-taxi-data/2011/05/data.parquet ursa-labs-taxi-data/2011/06/data.parquet ursa-labs-taxi-data/2011/07/data.parquet ursa-labs-taxi-data/2011/08/data.parquet ursa-labs-taxi-data/2011/09/data.паркет ursa-labs-taxi-data/2011/10/data.
 parquet
...
parquet
...
Затем набор данных можно использовать с pyarrow.dataset.Dataset.to_table() или pyarrow.dataset.Dataset.to_batches() , как для локального.
Примечание
Можно загружать разделенные данные также в стрелке ipc формате или в формате пера.
Предупреждение
Если приведенный выше код выдает ошибку, скорее всего, причина в вашем
Учетные данные AWS не заданы. Следуйте этим инструкциям, чтобы получить Идентификатор ключа доступа AWS и Секретный ключ доступа AWS :
Учетные данные AWS.
Учетные данные обычно хранятся в ~/.aws/credentials (на Mac или Linux)
или в файле C:\Users\ (в Windows).
Вам нужно будет либо создать, либо обновить этот файл в соответствующем месте.
Содержимое файла должно выглядеть следующим образом:
[по умолчанию] aws_access_key_id=<ВАШ_AWS_ACCESS_KEY_ID> aws_secret_access_key=<ВАШ_AWS_SECRET_ACCESS_KEY>
Дан массив из 100 чисел от 0 до 99
импортировать numpy как np импортировать pyarrow как pa массив = pa.
 array (np.arange (100))
print(f"{обр[0]} .. {обр[-1]}")
array (np.arange (100))
print(f"{обр[0]} .. {обр[-1]}")
0 .. 99
Чтобы записать его в файл Feather, поскольку Feather хранит несколько столбцов,
мы должны создать из него pyarrow.Table ,
чтобы мы получили таблицу из одного столбца, которую затем можно
записывается в файл Feather.
таблица = pa.Table.from_arrays([arr], имена=["col1"])
Как только у нас есть таблица, ее можно записать в Feather File
используя функции модуля pyarrow.feather
импортировать pyarrow.feather как ft ft.write_feather (таблица, 'example.feather')
При наличии файла Feather его можно прочитать обратно в pyarrow . Таблица с помощью функции pyarrow.feather.read_table()
импортировать pyarrow.feather как ft
таблица = ft.read_table("пример.перо")
Результирующая таблица будет содержать те же столбцы, которые существовали в
паркетная пилка Блокированный массив
принт(таблица)
pyarrow.
 Таблица
столбец1: int64
----
столбец1: [[0,1,2,3,4,...,95,96,97,98,99]]
Таблица
столбец1: int64
----
столбец1: [[0,1,2,3,4,...,95,96,97,98,99]]
Arrow имеет встроенную поддержку JSON с разделителями строк. Каждая строка представляет строку данных в виде объекта JSON.
Даны некоторые данные в файле, где каждая строка является объектом JSON. содержащий строку данных:
импортировать временный файл
с tempfile.NamedTemporaryFile(delete=False, mode="w+") как f:
f.write('{"a": 1, "b": 2.0, "c": 1}\n')
f.write('{"a": 3, "b": 3.0, "c": 2}\n')
f.write('{"a": 5, "b": 4.0, "c": 3}\n')
f.write('{"a": 7, "b": 5.0, "c": 4}\n')
Содержимое файла можно прочитать обратно в pyarrow.Table с помощью pyarrow.json.read_json() :
импортировать пирроу как па импортировать pyarrow.json таблица = pa.json.read_json(f.name)
печать (таблица.to_pydict())
{'a': [1, 3, 5, 7], 'b': [2.0, 3.0, 4.0, 5.0], 'c': [1, 2, 3, 4]}
Arrow обеспечивает поддержку записи файлов в сжатых форматах,
оба для форматов, которые изначально обеспечивают сжатие, таких как Parquet или Feather,
и для форматов, которые не поддерживают стандартное сжатие, например CSV.
Дана таблица:
таблица = pa.table([
pa.массив([1, 2, 3, 4, 5])
], имена=["числа"])
Запись сжатых данных Parquet или Feather управляется аргумент сжатия для pyarrow.feather.write_feather() и pyarrow.parquet.write_table() функций:
pa.feather.write_feather(таблица, "compressed.feather",
сжатие = "lz4")
pa.parquet.write_table(таблица, "сжатый.паркет",
сжатие = "lz4")
Полную информацию можно найти в документации по каждой из этих функций. список поддерживаемых форматов сжатия.
Примечание
Стрелка фактически использует сжатие по умолчанию при записи
Паркетные или перьевые пилки. Feather сжимается с помощью lz4 по умолчанию, а Parquet по умолчанию использует snappy .
Для форматов, которые изначально не поддерживают сжатие, например CSV,
можно сохранить сжатые данные, используя pyarrow. :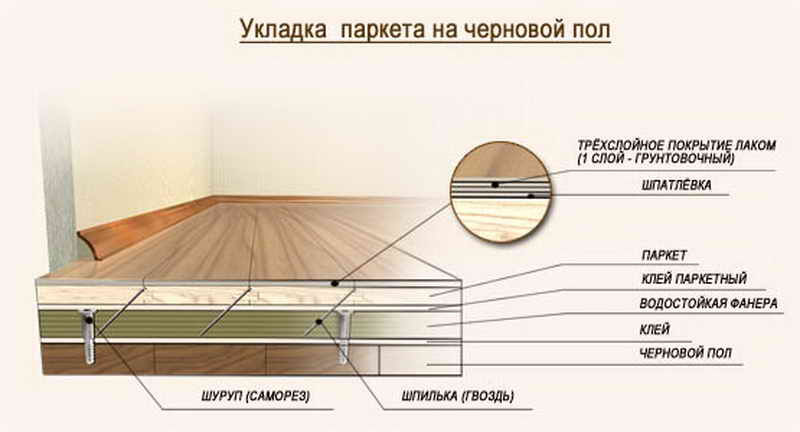 CompressedOutputStream
CompressedOutputStream
с pa.CompressedOutputStream("compressed.csv.gz", "gzip") как out:
pa.csv.write_csv(таблица, выход)
Это требует распаковки файла при обратном чтении,
что можно сделать с помощью pyarrow.CompressedInputStream как описано в следующем рецепте.
Arrow поддерживает чтение сжатых файлов, оба для форматов, которые предоставляют его изначально, например Parquet или Feather, а для файлов в форматах, изначально не поддерживающих сжатие, как CSV, но были сжаты приложением.
Чтение сжатых форматов, которые имеют встроенную поддержку сжатия
не требует особого обращения. Мы можем, например, прочитать обратно
файлы Parquet и Feather, которые мы написали в предыдущем рецепте
просто вызвав pyarrow.feather.read_table() и pyarrow.parquet.read_table() :
table_feather = pa.feather.read_table("сжатый.feather")
печать (table_feather)
pyarrow.Таблица числа: int64 ---- числа: [[1,2,3,4,5]]
table_parquet = pa.
 parquet.read_table("сжатый.parquet")
печать (таблица_паркет)
parquet.read_table("сжатый.parquet")
печать (таблица_паркет)
pyarrow.Таблица числа: int64 ---- числа: [[1,2,3,4,5]]
Чтение данных из форматов, которые не имеют встроенной поддержки
вместо этого сжатие включает их распаковку перед декодированием.
Это можно сделать с помощью класса pyarrow.CompressedInputStream .
который оборачивает файлы операцией распаковки до того, как результат будет
предоставляется фактической функции чтения.
Например, чтобы прочитать сжатый файл CSV:
с pa.CompressedInputStream(pa.OSFile("compressed.csv.gz"), "gzip") в качестве входных данных:
table_csv = pa.csv.read_csv (ввод)
печать (таблица_csv)
pyarrow.Таблица числа: int64 ---- числа: [[1,2,3,4,5]]
Примечание
В случае с CSV стрелка на самом деле достаточно умна, чтобы попытаться обнаружить
сжатые файлы с использованием расширения файла. Итак, если ваш файл называется *.gz или *.bz2 функция pyarrow. будет
попробуй распаковать соответственно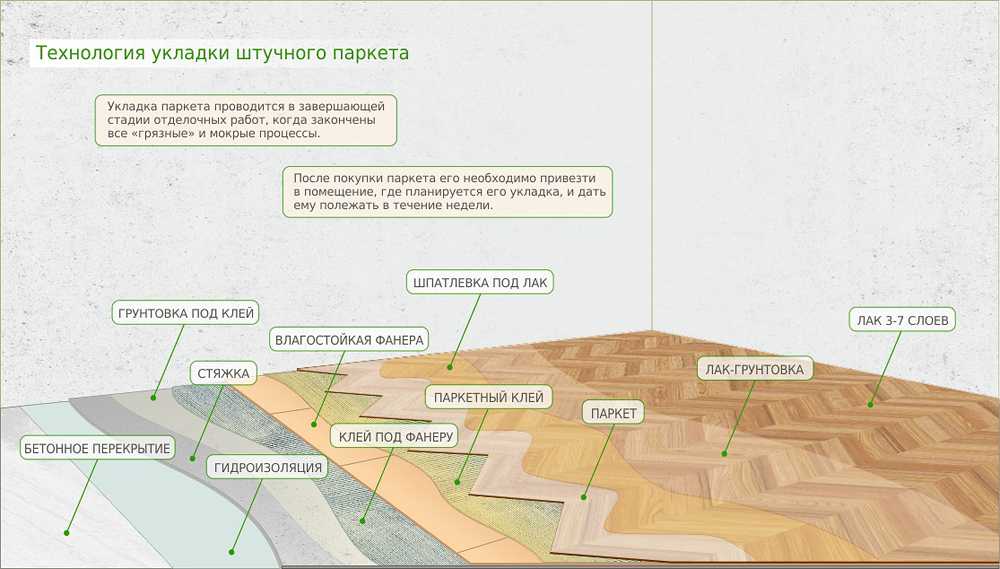 csv.read_csv()
csv.read_csv()
table_csv2 = pa.csv.read_csv("сжатый.csv.gz")
печать (таблица_csv2)
pyarrow.Таблица числа: int64 ---- числа: [[1,2,3,4,5]]
Создание заданий рецепта AWS Glue DataBrew и работа с ними
Использование задания рецепта DataBrew для очистки и нормализации данных в DataBrew набор данных и записать результат в место вывода по вашему выбору. Запуск задания рецепта не влияет на набор данных или базовые исходные данные. Когда задание выполняется, оно подключается к исходным данным только для чтения. Вывод задания записывается в вывод расположение, указанное вами в Amazon S3, каталоге данных AWS Glue или поддерживаемой базе данных JDBC.
Используйте следующую процедуру для создания задания рецепта DataBrew.
Чтобы создать задание рецепта
Войдите в консоль управления AWS и откройте консоль DataBrew по адресу https://console.
aws.amazon.com/databrew/.Выберите ЗАДАНИЯ на панели навигации, выберите Задания рецептов и выберите Создать работа .
Введите имя для своей работы, а затем выберите Создать задание рецепта .
Для ввода задания введите сведения о задании, которое вы хотите создать: имя набора данных для обработки и рецепт для использования.
Задание рецепта использует рецепт DataBrew для преобразования набора данных. Чтобы использовать рецепт, убедитесь, что опубликуйте его первым.
Настройте параметры вывода задания.
Укажите место назначения для вывода вашего задания. Если у вас не настроено соединение DataBrew для назначения вывода сначала настройте его на вкладке DATASETS как описано в Поддерживаемые соединения для источников данных и выходов.
Выберите один из
следующие направления вывода:Amazon S3, с поддержкой каталога данных AWS Glue или без нее
Amazon Redshift с поддержкой каталога данных AWS Glue или без нее
JDBC
Таблицы Snowflake с базой данных Amazon ADS
3
- 0
- 0 Данные клея WS Поддержка каталога. Таблицы базы данных Amazon RDS поддерживают следующие двигатели баз данных:
Amazon S3 с поддержкой каталога данных AWS Glue.
Для вывода каталога данных AWS Glue на основе AWS Lake Formation DataBrew поддерживает только замена существующих файлов. В этом подходе файлы заменяются на сохраните существующие разрешения Lake Formation для вашей роли доступа к данным. Кроме того, DataBrew отдает предпочтение местоположению Amazon S3 из каталога данных AWS Glue.
стол. Таким образом, вы не можете переопределить местоположение Amazon S3 при создании рецепта.
работа.В некоторых случаях местоположение Amazon S3 в выходных данных задания отличается от местоположения Amazon S3 в данных. Каталожный стол. В этих случаях DataBrew автоматически обновляет определение задания. с местоположением Amazon S3 из таблицы каталога. Это происходит, когда вы обновляете или начать свои существующие рабочие места.
Только для мест назначения вывода Amazon S3 у вас есть дополнительные варианты:
Выберите один из доступных форматов вывода данных для Amazon S3, необязательно сжатие и необязательный настраиваемый разделитель. Поддерживаемые разделители для выходные файлы такие же, как и входные: запятая, двоеточие, точка с запятой, вертикальная черта, табуляция, знак вставки, обратная косая черта и пробел.
Подробнее о форматировании см.
следующую таблицу.Формат Расширение файла (без сжатия) Расширения файлов (сжатые) Значения, разделенные запятыми
.csv.csv.snappy,.csv.gz,.csv.lz4,csv.bz2,.csv.deflate,csv.brЗначения, разделенные табуляцией
. csv .tsv.snappy,.tsv.gz,.цв.лз4,цв.бз2,.цв.дефлат,цв.брПаркет Apache .паркет.parquet.snappy,.parquet.gz,.parquet.lz4,.parquet.lzo,.паркет.brПаркетный клей AWS Не поддерживается .клей.паркет.щелчокАпач Авро .авро.avro.snappy,., avro.gz .avro.lz4,.avro.bz2,.avro.deflate,.avro.brApache ORC .орк.orc.snappy,.orc.lzo,.orc.zlibXML .xml.xml.snappy,.xml.gz,.xml.lz4,.xml.bz2,.xml.deflate,.xml.brJSON (только формат строк JSON) .json., json.snappy .json.gz,.json.lz4,json.bz2,.json.deflate,.json.brТабло Hyper Не поддерживается Неприменимо Выберите, следует ли выводить один файл или несколько файлов. Есть три вариантов вывода файлов с Amazon S3:
Автоматически создавать файлы (рекомендуется) — DataBrew определяет оптимальные количество выходных файлов.
Выход в один файл сгенерировано. Этот параметр может привести к дополнительному выполнению задания.
время, потому что требуется постобработка.Вывод нескольких файлов – Вы указали количество файлов для результат вашей работы. Допустимые значения: 2–999. Меньше файлов, чем у вас спецификация может быть выведена, если используется разделение столбцов или если количество строк в выводе меньше, чем количество файлов вы указываете.
(Необязательно) Выберите разделение столбцов для вывода задания рецепта.
Разбиение столбцов обеспечивает еще один способ разделения выходных данных задания рецепта на несколько файлы. Разделение столбцов можно использовать с новыми или существующими выходными данными Amazon S3 или с новым каталогом данных Amazon S3.
выход. Его нельзя использовать с существующими таблицами каталога данных Amazon S3. Выходные файлы основаны на
значения имен столбцов, которые вы указываете. Если указанные вами имена столбцов уникальны, результирующий файл Amazon S3
пути к папкам основаны на порядке имен столбцов.Пример разделения столбцов см. в разделе Пример разделения столбцов далее.
(необязательно) Выберите Включить шифрование выходных данных задания , чтобы зашифровать выходных данных задания, которые DataBrew записывает в ваше выходное местоположение, а затем выберите шифрование метод:
Использовать шифрование SSE-S3 — вывод зашифрованы с использованием шифрования на стороне сервера с ключами шифрования, управляемыми Amazon S3.
Использовать службу управления ключами AWS (AWS KMS) — выходные данные зашифрованы с помощью AWS KMS. Чтобы использовать этот вариант, выберите имя ресурса Amazon (ARN) ключа AWS KMS. что вы хотите использовать. Если у вас нет ключа AWS KMS, вы можете создать его, выбрав Создайте ключ AWS KMS .
Для разрешений на доступ выберите роль AWS Identity and Access Management (IAM), которая позволяет DataBrew напишите в место выхода. Для местоположения, принадлежащего вашему AWS аккаунт, вы можете выбрать
AwsGlueDataBrewDataAccessRoleроль, управляемая сервисом. Это позволит DataBrew получить доступ к ресурсам AWS, которые вы собственный.На панели Дополнительные параметры задания можно выбрать дополнительные параметры.
для того, как ваша работа должна работать:Максимальное количество единиц – процессы DataBrew задания, использующие несколько вычислительных узлов, работающих параллельно. По умолчанию количество узлов 5. Максимальное количество узлов 149.
Тайм-аут задания — Если задание занимает больше количество минут, которое вы установили здесь для запуска, оно завершается с ошибкой по тайм-ауту ошибка. Значение по умолчанию — 2880 минут или 48 часов.
Количество повторных попыток — Если задание завершается работает, DataBrew может попытаться запустить его снова. По умолчанию задание не повторил попытку.
Включить журналы Amazon CloudWatch для задания — разрешить публикацию DataBrew диагностическую информацию в журналы CloudWatch. Эти журналы могут быть полезны для в целях устранения неполадок или для получения более подробной информации о работе. обработанный.
Для Расписание заданий можно применить расписание заданий DataBrew, чтобы ваша работа выполняется в определенное время или периодически. Для большего сведения см. в разделе Автоматизация выполнения заданий по расписанию.
Когда настройки будут такими, как вы хотите, выберите Создать работа . Или, если вы хотите запустить задание немедленно, выберите Создать и запустить задание .
 aws.amazon.com/databrew/.
aws.amazon.com/databrew/. Выберите один из
следующие направления вывода:
Выберите один из
следующие направления вывода: стол. Таким образом, вы не можете переопределить местоположение Amazon S3 при создании рецепта.
работа.
стол. Таким образом, вы не можете переопределить местоположение Amazon S3 при создании рецепта.
работа.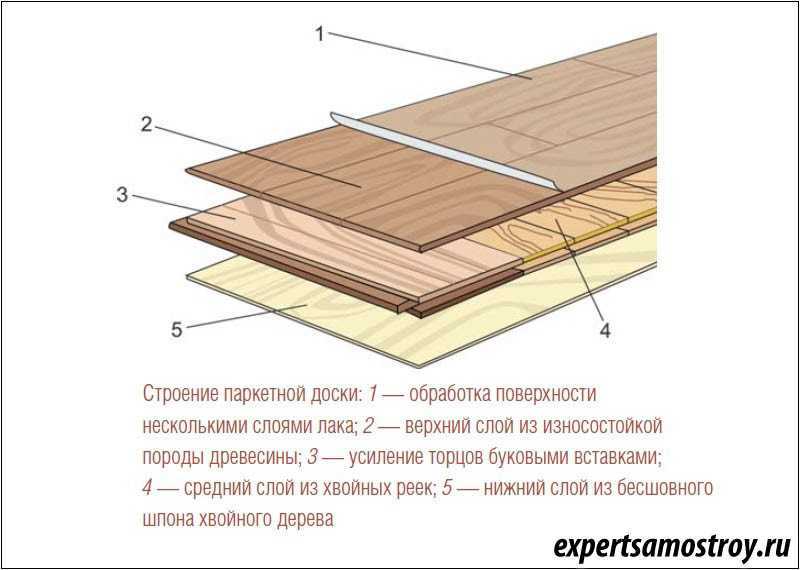 Подробнее о форматировании см.
следующую таблицу.
Подробнее о форматировании см.
следующую таблицу. csv
csv  avro.gz
avro.gz  json.snappy
json.snappy  время, потому что требуется постобработка.
время, потому что требуется постобработка. выход. Его нельзя использовать с существующими таблицами каталога данных Amazon S3. Выходные файлы основаны на
значения имен столбцов, которые вы указываете. Если указанные вами имена столбцов уникальны, результирующий файл Amazon S3
пути к папкам основаны на порядке имен столбцов.
выход. Его нельзя использовать с существующими таблицами каталога данных Amazon S3. Выходные файлы основаны на
значения имен столбцов, которые вы указываете. Если указанные вами имена столбцов уникальны, результирующий файл Amazon S3
пути к папкам основаны на порядке имен столбцов.
 для того, как ваша работа должна работать:
для того, как ваша работа должна работать:

Вы можете следить за ходом выполнения задания, проверяя его статус во время выполнения задания. бег. Когда выполнение задания завершено, статус меняется на Успешно . Результат задания теперь доступен в выбранном вами место выхода.
DataBrew сохраняет определение вашего задания, чтобы вы могли запустить его позже. Чтобы повторно запустить job, выберите Jobs на панели навигации. Выберите работу, которую вы хотите работать, а затем выберите Выполнить задание .
Пример разделения столбцов
В качестве примера разделения столбцов предположим, что вы указали три столбца, каждый
строка которого содержит одно из двух возможных значений. Dept колонка может
иметь значение Admin или англ .
Столбец Штатный тип может иметь значение Неполный рабочий день или Полная занятость . Столбец
Столбец Location может иметь значение Office1 или Office2 . Сегменты Amazon S3 для вашей работы
вывод выглядит примерно следующим образом.
s3://bucket/output-folder/Dept=Admin/Staff-type=Part-time/Area=Office1/jobId_timestamp_part0001.csv s3://bucket/output-folder/Dept=Admin/Staff-type=Part-time/Location=Office2/jobId_timestamp_part0002.csv s3://bucket/output-folder/Dept=Admin/Staff-type=Full-time/Location=Office1/jobId_timestamp_part0003.csv s3://bucket/output-folder/Dept=Admin/Staff-type=Full-time/Location=Office2/jobId_timestamp_part0004.csv s3://bucket/output-folder/Dept=Eng/Staff-type=Part-time/Location=Office1/jobId_timestamp_part0005.csv s3://bucket/output-folder/Dept=Eng/Staff-type=Part-time/Location=Office2/jobId_timestamp_part0006.csv s3://bucket/output-folder/Dept=Eng/Staff-type=Full-time/Location=Office1/jobId_timestamp_part0007.csv s3://bucket/output-folder/Dept=Eng/Staff-type=Full-time/Location=Office2/jobId_timestamp_part0008.
 csv
csv Автоматизация выполнения заданий по расписанию
Вы можете повторно запускать задания DataBrew в любое время, а также автоматизировать выполнение заданий DataBrew по расписанию.
Повторное выполнение задания DataBrew
Войдите в консоль управления AWS и откройте консоль DataBrew на https://console.aws.amazon.com/databrew/.
На панели навигации выберите Задания . Выберите работу, которую вы хотите для запуска, а затем выберите Выполнить задание .
Чтобы запускать задание DataBrew в определенное время или периодически, создайте задание DataBrew. расписание. Затем вы можете настроить выполнение задания в соответствии с расписанием.
Для создания расписания заданий DataBrew
На панели навигации консоли DataBrew выберите Вакансии .
Выберите вкладку Расписания ,
и выберите Добавить расписание .Введите имя для своего расписания, а затем выберите значение для Выполнить. частота :
Повторяющийся — Выберите, как часто вы хотите задание для запуска (например, каждые 12 часов). Затем выберите день или дни для запуска работа на. При желании вы можете ввести время суток, когда задание выполняется.
В определенное время - Введите время суток, когда вы хотите получить работу бежать. Затем выберите, в какой день или дни выполнять задание.
Введите CRON — определите расписание работы, введя действительный cron выражение. Дополнительные сведения см. в разделе Работа с выражениями cron для заданий рецептов.
Когда настройки будут такими, как вы хотите, выберите Сохранить .
 Выберите вкладку Расписания ,
и выберите Добавить расписание .
Выберите вкладку Расписания ,
и выберите Добавить расписание .
Чтобы связать задание с расписанием
На панели навигации выберите Jobs .
Выберите задание, с которым вы хотите работать, а затем для Действия выберите Редактировать. .
На панели Расписание заданий выберите Связать график . Выберите имя расписания, которое вы хотите использовать.
Когда настройки будут такими, как вы хотите, выберите Сохранить .
Работа с выражениями cron для заданий рецептов
Выражения Cron имеют шесть обязательных полей, разделенных пробелом. синтаксис следующий.
МинутыЧасыДень месяцаМесяцДень неделиГод
В приведенном выше синтаксисе следующие значения и подстановочные знаки используются для указанного
поля.
| Поля | Значения | Подстановочные знаки |
|---|---|---|
Минуты | 0–59 | , - */ |
часов | 0–23 | , - */ |
День месяца | 1–31 | , - * ? / Д Ш |
Месяц | 1–12 или январь-декабрь | , - */ |
День недели | 1–7 или вс-сб | , - * ? / л |
Год | 1970–2199 | , - */ |
Используйте эти подстановочные знаки следующим образом:
Подстановочный знак , (запятая) включает дополнительные значения.
В
поле Месяц,ЯНВ, ФЕВ, МАРвключает январь, февраль и март.Подстановочный знак - (в тире) указывает диапазоны. в
Поле Day, 1–15 включает дни с 1 по 15 указанный месяц.Подстановочный знак * (звездочка) включает все значения в поле. В поле
часов* включает каждый час.Подстановочный знак / (косая черта) задает приращения. в
Минутыполе, вы можете ввести1/10для указать каждую 10-ю минуту, начиная с первой минуты часа (для например, 11-я, 21-я и 31-я минуты).? (вопросительный знак) подстановочный знак указывает тот или иной.
Например, предположим, что в поле День месяцавы вводите 7 . Если бы вам было все равно, в какой день недели седьмой был, можно тогда ввести ? вДень неделиполе.Подстановочный знак L в
День месяцаилиПоле Day-of-weekуказывает последний день месяца или неделя.Подстановочный знак W в поле
День месяцауказывает день недели. В полеДень месяцавведите3Wуказывает день, ближайший к третьему дню недели месяца.
 В
поле
В
поле 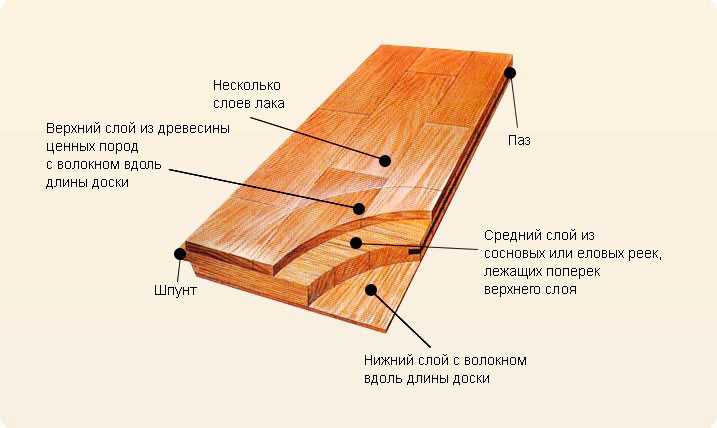 Например, предположим, что в поле
Например, предположим, что в поле Эти поля и значения имеют следующие ограничения:
Нельзя указать
День месяцаиДень неделиполя в том же выражении cron. Если вы укажете значение в одном из полей,
вы должны использовать ? (вопросительный знак) в другой.Выражения Cron, которые приводят к скорости более 5 минут, не поддерживаются.
 Если вы укажете значение в одном из полей,
вы должны использовать ? (вопросительный знак) в другой.
Если вы укажете значение в одном из полей,
вы должны использовать ? (вопросительный знак) в другой.При создании расписания можно использовать следующие образцы строк cron.
| Минуты | часов | День месяца | Месяц | День недели | Год | Значение |
|---|---|---|---|---|---|---|
0 | 10 | * | * | ? | * | Запускать в 10:00 (UTC) каждый день |
15 | 12 | * | * | ? | * | Запускать в 12:15 (UTC) каждый день |
0 | 18 | ? | * | ПН-ПТ | * | Запуск в 18:00 (UTC) с понедельника по пятницу |
0 | 8 | 1 | * | ? | * | Запускать в 8:00 (UTC) каждого первого дня месяца |
0/15 | * | * | * | ? | * | Запускать каждые 15 минут |
0/10 | * | ? | * | ПН-ПТ | * | Запускать каждые 10 минут с понедельника по пятницу |
0/5 | 8–17 | ? | * | ПН-ПТ | * | Запускать каждые 5 минут с понедельника по пятницу с 8:00 до 17:55 (UTC) |
Например, вы можете использовать следующее выражение cron для запуска задания каждый день в 12:15.